
This article summarizes our findings from “Out of Sight, Out of Mind: Detecting Orphaned Web Pages at Internet-Scale”, by Stijn Pletinckx, Kevin Borgolte, and Tobias Fiebig. The paper will appear at the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS ’21), November 15–19.
You can find a copy of the paper here:
We want to build an Internet of secure things. When we look at how we interact with the Internet, we inevitably end up with the World Wide Web. In fact, for most people today, the World Wide Web—the part of the Internet you access with your web browser—IS the Internet.
At the same time, the World Wide Web is incredibly old. Well, at least old enough for everyone under 30 to be younger than the Internet. And with the Internet getting older, things that once were there, might have been forgotten. And—all ring-related analogies aside—these forgotten things, or web pages, may become serious problems.
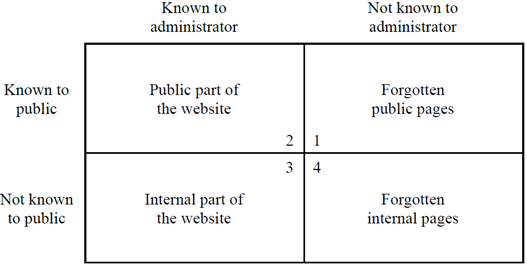
When we thing about websites, there are two types of people: Those running the site—administrators—and those using the site—the public. When it comes to pages on sites, these might be in active use, or simply forgotten.
Forgetting websites
One might ask: How can a website be forgotten? Well, imagine you are hosting a party. To know who comes, and who brings what (salad, drinks, music) you set up a small RSVP form on your website and link it from the main page. After the party, you remove the link from the website, but leave the page with the actual registration form in place. And, over time, you might forget that it ever was there, while—when accessed via its direct URL—the webform still happily accepts registrations for your party.
Why should this be a problem?
One might now wonder why this might even be a problem? The page—at least at some point—was supposed to be where it is, and was—assuming the best here—also written in the most secure way the authors knew. However, we all know that software—unlike good wine—does not get better with age. Researchers find new methods of exploitation, and simple bugs might just have slipped by. The major problem here is that we cannot update what we do not know exists; And the most secure piece of software is… well, software that does not run.

Finding Orphans
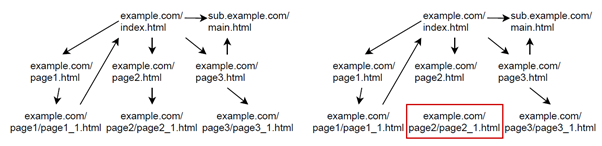
So, how do we find these orphaned pages on the web? Well, we first need a list of all pages currently reachable from the main page of a website. This one is easily gotten by doing a crawl of a website from the main page on, i.e., we start at the main page and follow each link, and do the same for each linked page we find, until we do not find new links anymore. Then, we need a list of all pages that were accessible from the main-page of a web-site in the past. We then only have to check if those pages that are no longer reachable via the main page are still there, and still look the same as when they were accessible from the main page. Sounds easy enough.
The Internet Archive
To get the two lists—pages that used to be there and pages that are there now—we leverage the Internet Archive. The Internet Archive, with it’s WaybackMachine (https://archive.org/web/), regularly crawls a major portion of the Web and archives the pages it finds. We can look at the most recent version crawled of a website by the WaybackMachine, and then check for each older site map, if all links we see are still in the most recent version.
For those that disappeared in between, we can then compare the last version the WaybackMachine recorded for it with what we see when we retrieve the page right at that moment.
If the two still match, we found an orphan. In our paper, you can learn more about the additional checks we performed to see whether pages are really orphaned.
Orphans and Security
How are doing orphans in terms of security? In the beginning, we assumed that orphaned pages might be more likely to be vulnerable to common web vulnerabilities. Now we can check! We indeed find that orphaned pages are more vulnerable to common web issues like cross-site-scripting (XSS) and SQL injection (SQLi) vulnerabilities. In our sample of orphaned pages, we found that orphaned pages are up to 10x as vulnerable to selected vulnerabilities than a random set of (non-orphaned) pages from the Internet! Interestingly, websites which did have orphaned pages were also slightly more susceptible to vulnerabilities than a random sample of websites.
So, what does this mean in plain English? Well, orphans are bad for security, and if you run your system in a way that leads to the accumulation of orphans, you are also a bit more likely to have vulnerabilities on your non-orphaned pages. Security posture matters!
Conclusion
Orphaned web pages are out there, and they are a serious concern! If you want to learn more on how you can find them, check out our paper (https://research.tudelft.nl/en/publications/out-of-sight-out-of-mind-detecting-orphaned-web-pages-at-internet) and the open-source implementation of our toolchain (https://github.com/OrphanDetection/orphan-detection). And please always feel to reach out of you have any questions!

0 Comments